tugas analisis sentimen deep learning
nama kelompok
Adi Nugraha Y 50414234
M Ulil Amri 57414576
M Ilham Afemi 57414327
Rio Octaviano 59414462
Disini kita menggunakan bahasa phyton untuk melakukan analisa sentimen, serta kita pilih API twitter. Fokus analisa sentimen bertema pembulian. berikut caranya:
ketikan code program dibawah ini dan execute 1 per 1 pada IDLE phyton yang sudah diinstall, disini kita menggunakan phyton versi 3.6
import sys
import twitter # menangani API Twitter
import pandas as pd # menangani Data
import numpy as np # menangani Komputasi angka
# For plotting and visualization:
from IPython.display import display
import matplotlib.pyplot as plt
import seaborn as sns
from textblob import TextBlob
import re
#############################################################
QUERY = "autism" # keyword yang mau dicari
COUNT = 30 # banyak tweet yang ingin didapat
'''
kode konsumer dan access token didapat dari
registrasi aplikasi client
'''
#consumers
C_KEY = 'jOpIWjAivmBusTjtUffWXVk0A'
C_SEC = 'JFdRhvIJICqDUed0h2y2RIpL5wQHex6QmOixmXCzPeZQjw5dQj'
#access token
AT_KEY = '974493124125802496-byVzjdQH1eirceDZ7cl560jw8Bc7qYG'
AT_SEC = 'm3S02Ek7ucAd4R7ncEoyYaNEMJnZvvUZ6dnmT9ORehY3V'
#############################################################
api = twitter.Api(consumer_key=C_KEY, consumer_secret=C_SEC,
access_token_key=AT_KEY, access_token_secret=AT_SEC)
tweets = api.GetSearch(
raw_query="q=%s&count=%i&result_type=recent&lang=en" % (QUERY,COUNT))
# membentuk data frame dengan kolom Tweets
data = pd.DataFrame(data=[tweet.text for tweet in tweets], columns=['Tweets'])
# tampilkan deret data pada dataframe
display(data.head(COUNT))
# tambahkan data lainnya yang mendukung
data['len'] = np.array([len(tweet.text) for tweet in tweets])
data['ID'] = np.array([tweet.id for tweet in tweets])
data['Date'] = np.array([tweet.created_at for tweet in tweets])
data['Source'] = np.array([tweet.source for tweet in tweets])
data['Likes'] = np.array([tweet.favorite_count for tweet in tweets])
data['RTs'] = np.array([tweet.retweet_count for tweet in tweets])
# hitung rata-rata banyak data
mean = np.mean(data['len'])
def clean_tweet(tweet):
'''
fungsi ini bertugas untuk membersihkan tweet dari
selain abjad dan angka dengan memanfaatkan format
regex
'''
return ' '.join(
re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", tweet).split())
def analize_sentiment(tweet):
'''
fungsi ini bertugas untuk memisahkan polaritas tweet
dengan menggunakan textblob
'''
analysis = TextBlob(clean_tweet(tweet))
if analysis.sentiment.polarity > 0:
return 1
elif analysis.sentiment.polarity == 0:
return 0
else:
return -1
# buat kolom yang berisi hasil analisis sentimen
data['SA'] = np.array([ analize_sentiment(tweet) for tweet in data['Tweets'] ])
# buat deret pengelompokkan tweets
pos_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] > 0]
net_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] == 0]
neg_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] < 0]
# Cetak persentase
print(("\n\nAnalisis sentimen Bahasa Inggris terhadap kata %s sebanyak %i tweet\n"+ \
" - Positif : %.2f\n"+ \
" - Netral : %.2f\n"+ \
" - Negatif : %.2f\n") % (\
QUERY, COUNT, \
(len(pos_tweets)*100/len(data['Tweets'])),\
(len(net_tweets)*100/len(data['Tweets'])),\
(len(neg_tweets)*100/len(data['Tweets'])) \
)\
)
#selesai
sys.exit(0)
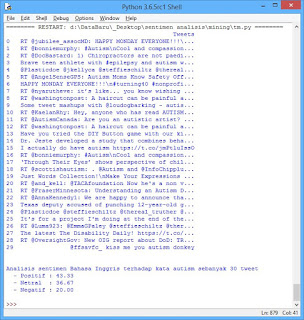
ini adalah output yang di hasilkan program diatas
Adi Nugraha Y 50414234
M Ulil Amri 57414576
M Ilham Afemi 57414327
Rio Octaviano 59414462
Disini kita menggunakan bahasa phyton untuk melakukan analisa sentimen, serta kita pilih API twitter. Fokus analisa sentimen bertema pembulian. berikut caranya:
ketikan code program dibawah ini dan execute 1 per 1 pada IDLE phyton yang sudah diinstall, disini kita menggunakan phyton versi 3.6
import sys
import twitter # menangani API Twitter
import pandas as pd # menangani Data
import numpy as np # menangani Komputasi angka
# For plotting and visualization:
from IPython.display import display
import matplotlib.pyplot as plt
import seaborn as sns
from textblob import TextBlob
import re
#############################################################
QUERY = "autism" # keyword yang mau dicari
COUNT = 30 # banyak tweet yang ingin didapat
'''
kode konsumer dan access token didapat dari
registrasi aplikasi client
'''
#consumers
C_KEY = 'jOpIWjAivmBusTjtUffWXVk0A'
C_SEC = 'JFdRhvIJICqDUed0h2y2RIpL5wQHex6QmOixmXCzPeZQjw5dQj'
#access token
AT_KEY = '974493124125802496-byVzjdQH1eirceDZ7cl560jw8Bc7qYG'
AT_SEC = 'm3S02Ek7ucAd4R7ncEoyYaNEMJnZvvUZ6dnmT9ORehY3V'
#############################################################
api = twitter.Api(consumer_key=C_KEY, consumer_secret=C_SEC,
access_token_key=AT_KEY, access_token_secret=AT_SEC)
tweets = api.GetSearch(
raw_query="q=%s&count=%i&result_type=recent&lang=en" % (QUERY,COUNT))
# membentuk data frame dengan kolom Tweets
data = pd.DataFrame(data=[tweet.text for tweet in tweets], columns=['Tweets'])
# tampilkan deret data pada dataframe
display(data.head(COUNT))
# tambahkan data lainnya yang mendukung
data['len'] = np.array([len(tweet.text) for tweet in tweets])
data['ID'] = np.array([tweet.id for tweet in tweets])
data['Date'] = np.array([tweet.created_at for tweet in tweets])
data['Source'] = np.array([tweet.source for tweet in tweets])
data['Likes'] = np.array([tweet.favorite_count for tweet in tweets])
data['RTs'] = np.array([tweet.retweet_count for tweet in tweets])
# hitung rata-rata banyak data
mean = np.mean(data['len'])
def clean_tweet(tweet):
'''
fungsi ini bertugas untuk membersihkan tweet dari
selain abjad dan angka dengan memanfaatkan format
regex
'''
return ' '.join(
re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", tweet).split())
def analize_sentiment(tweet):
'''
fungsi ini bertugas untuk memisahkan polaritas tweet
dengan menggunakan textblob
'''
analysis = TextBlob(clean_tweet(tweet))
if analysis.sentiment.polarity > 0:
return 1
elif analysis.sentiment.polarity == 0:
return 0
else:
return -1
# buat kolom yang berisi hasil analisis sentimen
data['SA'] = np.array([ analize_sentiment(tweet) for tweet in data['Tweets'] ])
# buat deret pengelompokkan tweets
pos_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] > 0]
net_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] == 0]
neg_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] < 0]
# Cetak persentase
print(("\n\nAnalisis sentimen Bahasa Inggris terhadap kata %s sebanyak %i tweet\n"+ \
" - Positif : %.2f\n"+ \
" - Netral : %.2f\n"+ \
" - Negatif : %.2f\n") % (\
QUERY, COUNT, \
(len(pos_tweets)*100/len(data['Tweets'])),\
(len(net_tweets)*100/len(data['Tweets'])),\
(len(neg_tweets)*100/len(data['Tweets'])) \
)\
)
#selesai
sys.exit(0)
ini adalah output yang di hasilkan program diatas

Komentar
Posting Komentar